
Most agencies treat blog content like an assembly line. A writer gets a keyword, writes an article, someone uploads it, and everyone moves on to the next one. There is no feedback loop, no data driving decisions, and no system connecting the work back to business outcomes.
We built something different. Over the past year, WE-DO has developed a six-phase AI blog content pipeline that connects keyword research directly to publishing and performance tracking, with every phase informed by real data and automated through AI tooling.
This post walks through the complete system, phase by phase.
Why We Built This
Content marketing fails when the phases are disconnected. A keyword researcher hands off a spreadsheet. A writer interprets it differently. An editor publishes without checking competitive positioning. Nobody circles back to see if the content actually ranked.
The cost of this disconnection compounds. You publish content that targets the wrong intent. You miss internal linking opportunities. You write 2,000 words when competitors are ranking with 800. You never refresh underperforming posts because nobody tracks them systematically.
Our pipeline solves this by making every phase data-informed and connected to the next.
The Six Phases
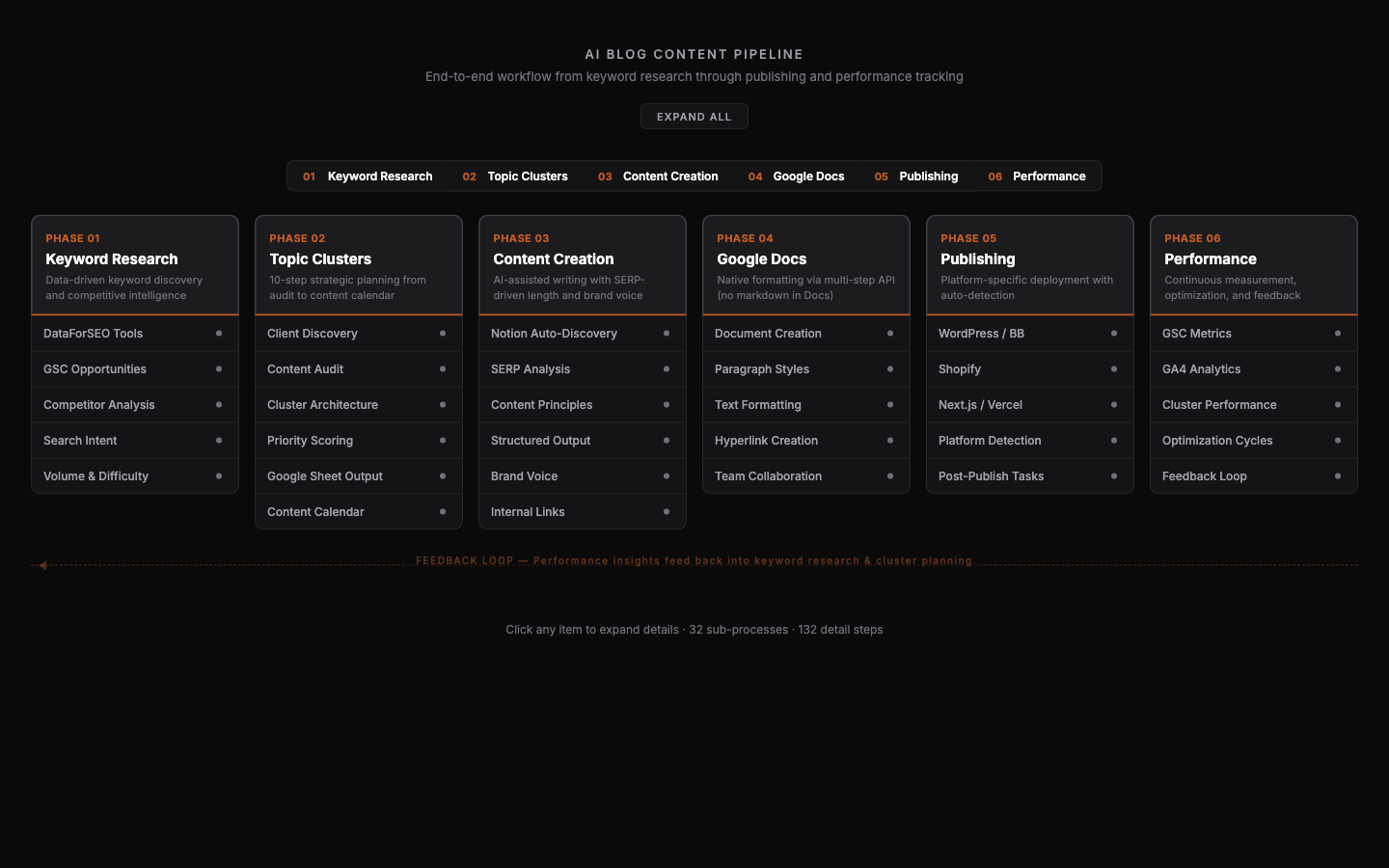
The pipeline flows left to right through six phases: Keyword Research, Topic Clusters, Content Creation, Google Docs, Publishing, and Performance. Each phase feeds the next, and performance data loops back to inform future keyword research.
Phase 1: Keyword Research
Everything starts with data, not gut feeling.
We use DataForSEO's API suite to build a comprehensive keyword picture. This includes keyword overview metrics, idea expansion (typically 200+ results per seed keyword), long-tail suggestions, related keywords at varying semantic depths, and bulk keyword difficulty scoring.
But raw keyword data is only half the picture. We cross-reference it with Google Search Console data, specifically looking at current rankings over a 90-day window. The most valuable opportunities often hide in keywords where you already have impressions but low click-through rates, or positions that have recently decayed.
Competitor analysis adds the third dimension. We identify the top three domain competitors, run keyword gap intersections to find terms they rank for that you don't, and parse their content to understand heading structures and content length patterns.
Every keyword gets classified by search intent (informational, commercial, transactional, or navigational) and scored for business alignment on a 1-5 scale. A keyword with 10,000 monthly searches but zero alignment to your services is worth less than one with 200 searches that maps directly to a revenue-generating page.
Phase 2: Topic Clusters
Raw keywords need structure. This phase organizes hundreds of keywords into a strategic content architecture.
We follow a systematic process that starts with client discovery: understanding business goals, building a product and service catalog, and defining geographic constraints. This context determines how keywords map to actual business value.
Next comes a content audit. We pull GSC rankings for the last 90 days, GA4 blog page performance metrics, and build an inventory of existing content. This prevents duplicate targeting and identifies refresh opportunities.
The cluster architecture groups keywords into semantic themes, each anchored by a pillar keyword (highest volume with strong business alignment). Each cluster contains 5 to 20 supporting keywords. We validate for overlap to ensure no two clusters compete for the same terms.
Priority scoring uses a weighted formula:
- Volume (30%) - Search demand
- Ease (25%) - Keyword difficulty relative to domain authority
- Business Alignment (25%) - How directly the keyword maps to services or products
- Competitive Gap (20%) - Opportunity where competitors are weak
The output is a six-tab Google Sheet workbook: Overview, Content Plan, Keyword Research, Competitor Gaps, Internal Links, and Existing Content Inventory. A content calendar distributes work across three months, with pillars and high-priority clusters first.
Phase 3: Content Creation
This is where most agencies just say "write a blog post." Our system is more deliberate.
Before writing a single word, the system automatically discovers context from Notion. It looks up the client record, extracts the content plan URL, fetches voice and tone documents, and identifies the publishing platform. This eliminates the "what does this client sound like?" guesswork that slows down production.
Then comes SERP analysis. We parse the top 10 results for the target keyword, measuring competitor word counts, heading structures, and content depth. The critical rule: we never use fixed word counts. If the top-ranking articles average 1,800 words, we target that range. If they average 600, writing 2,000 words wastes everyone's time and likely signals the wrong intent.
Content follows strict principles:
- Write TO the reader, not about them
- Lead with empathy before information
- One core message per article
- Flesch Reading Ease score between 60 and 70
- Maximum 2-3 sentences per paragraph
The structured output includes a title, SEO metadata block, empathetic opening hook, core insight, 3-5 actionable H2 sections, a single clear CTA, and a FAQ section. Internal links reference cluster siblings, pillar pages, and cross-links (capped at 2-3 per post to avoid over-optimization).
Phase 4: Google Docs Delivery
Here is something most people don't realize: Google Docs doesn't support markdown. If you paste markdown into a Google Doc, you get literal hash symbols and asterisks, not formatted headings and bold text.
Our system handles this through a multi-step API process:
- Document creation using the Google Drive API with plain text only (no markdown syntax)
- Character index mapping by reading the document back to get exact positions of every line
- Paragraph style application using the Google Docs API to apply TITLE, HEADING_2, and HEADING_3 styles
- Text formatting for bold key phrases, italic metadata, and colored secondary text
- Hyperlink insertion targeting specific character indices to create properly anchored internal links
This produces a Google Doc that looks professionally formatted and is ready for team review, with all internal links properly clickable and heading hierarchy intact.
The document lands in the client's shared folder, and the content team gets notified for review. Revision cycles happen directly in Google Docs where clients and editors are already comfortable working.
Phase 5: Publishing
Different clients use different platforms. Our pipeline detects the publishing platform from the client database and routes content to the correct workflow automatically.
WordPress with Beaver Builder gets deployed via SSH and WP-CLI. The HTML is imported into Beaver Builder's node structure, page templates are assigned, and caches are flushed post-deploy.
Shopify uses the Shopify MCP API to create articles, assign blog categories and tags, populate SEO meta fields, and upload featured images.
Next.js sites (like this one) follow a code-based workflow: adding metadata to the blog configuration file, creating an MDX content file, and pushing to GitHub for automatic Vercel deployment. The site rebuilds and goes live in 2-3 minutes.
After publishing on any platform, the system handles post-publish tasks: generating a 1200x630 hero image for social sharing, adding Article and FAQ schema markup, submitting to the sitemap, and updating the topic cluster sheet with the published status.
Phase 6: Performance Tracking
Publishing is not the finish line. It is the starting line for measurement.
We track performance across two data sources. Google Search Console provides clicks, impressions, average position, CTR by query, and indexing status. Google Analytics (GA4) provides sessions, engagement rate, bounce rate, and acquisition source breakdown.
But individual article metrics only tell part of the story. We track cluster-level performance: how pillar pages perform versus their cluster articles, keyword ranking movement across the entire topic group, internal link click-through rates, and emerging content gaps.
Optimization happens in defined cycles:
- 2 weeks post-publish: Baseline check, verify indexing
- 30 days: Performance review, identify quick wins (meta description rewrites for low CTR)
- 90 days: Full content audit, compare to initial targets
- Quarterly: Cluster reprioritization based on actual performance data
The feedback loop is the most important part of the entire pipeline. Performance data from Phase 6 feeds directly back into Phase 1, informing the next cycle of keyword research with real-world results rather than projections.
The Expanded View

When you expand every phase, the pipeline contains 32 sub-processes and 132 individual detail steps. Each one maps to a specific tool, API endpoint, or decision point in the workflow.
What This Means for Results
This pipeline changes the economics of content marketing in several ways.
Speed without sacrificing quality. Automated context gathering, SERP analysis, and document formatting eliminate hours of manual work per article without cutting corners on research or writing standards. This pipeline is a practical example of AI tools for business automation applied to content operations.
Data-informed decisions at every step. From keyword selection to word count to publishing timing, every decision is backed by actual data rather than best guesses or industry averages.
Systematic improvement. The feedback loop means every content cycle is informed by the previous one. Underperforming keywords get deprioritized. Successful patterns get amplified. Topic clusters evolve based on real ranking data.
Consistent execution across clients. Whether we're publishing to WordPress, Shopify, or a custom Next.js site, the research and creation process is identical. Only the final deployment step changes.
Getting Started
You don't need to build all six phases at once. Start with the feedback loop. If you're publishing content without tracking performance by keyword and cluster, you're flying blind.
Then work backward: build your topic cluster architecture, formalize your keyword research process, and standardize your content creation workflow. Each phase you systematize reduces the manual effort and increases the consistency of your output.
If you want to see how this pipeline would work for your content strategy, get in touch. We'll show you where your biggest content opportunities are hiding.
This pipeline is built on Claude Code's AI agents, MCP integrations, and custom skills. Read more about how we use Claude Code in our agency operations. For the strategic perspective on how content fits into the broader picture of using AI for marketing, see our comprehensive guide.



